
티스토리 뷰
개요
- 기술 분석: 분석 초기 데이터의 특징을 파악하기 위해 선택, 집계, 요약 등 양적 기술 분석을 수행한다.
- 탐색 분석: 업무 도메인 지식을 기반으로 대규모 데이터셋의 상관관계나 연관성을 파악한다.
- 추론 분석: 전통적인 통계분석 기법으로 문제에 대한 가설을 세우고 샘플링을 통해 가설을 검증한다.
- 인과 분석: 문제 해결을 위한 원인과 결과 변수를 도출하고 변수의 영향도를 분석한다.
- 예측 분석: 대규모 과거 데이터를 학습해 예측 모형을 만들고, 최근의 데이터로 미래를 예측한다.
- BigData 기반의 AI 예측 모델은 인간에 비해 객관적이며, 수백~수천개의 변수를 선정하여 이를 기반으로 예측 모델을 만들기 때문에 인간의 한계를 뛰어넘는 의사결정을 할 수 있게 되었다.
빅데이터 분석 프로세스
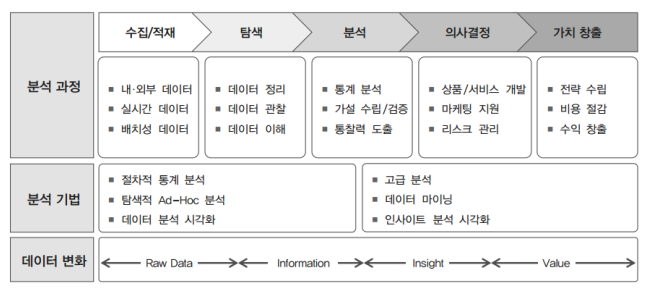
위의 빅데이터 분석 프로세스는 전통적인 방식의 분석과는 어떤 차이가 있을까?
- 분석 과정만 놓고 봤을 때는 둘의 방식에서 차이는 없다. 차이를 생각하기 위해서는 빅데이터의 요건인 3V + Long Data(오랜 기간동안 보관하는 데이터)를 생각해보아야 한다.
- 전통적인 기법에서는 3V에 대한 분석이 불가능했다면, 이를 가능하게 하는 것이 빅데이터 분석이라고 볼 수 있다.
빅데이터 분석 활용 기술
Impala - 임팔라
Hive가 MapReduce를 대체하는 SQL용 하둡 도구로 자리를 잡았으나, Hive는 MapReduce를 기반으로 하고 있기 때문에 인터렉티브한 데이터의 탐색적 분석에는 적합한 도구가 아니다. 따라서 빅데이터를 실시간으로 온라인 분석을 할 수 있는 개발한 프레임워크 중 하나가 임팔라이다.
- 주요 구성 요소
- Impalad
- 하둡의 데이터노드에 설치되어 임팔라의 실행 쿼리에 대한 계획, 스케줄링, 엔진을 관리하는 코어 영역이다.
- Query Planner
- 임팔라 쿼리에 대한 실행 계획을 수립한다.
- Query Coordinator
- 임팔라 job list 및 scheduling을 관리한다.
- Query Exec Engine
- 임팔라 쿼리를 최적화해 실행하고, 쿼리 결과를 제공한다.
- Statestored
- 분산 환경에 설치돼 있는 Impalad의 설정 정보 및 서비스를 관리한다.
- Catalogd
- 임팔라에서 실행된 작업 이력들을 관리하며, 필요 시 작업 이력을 제공한다.
- Impalad
- 아키텍처
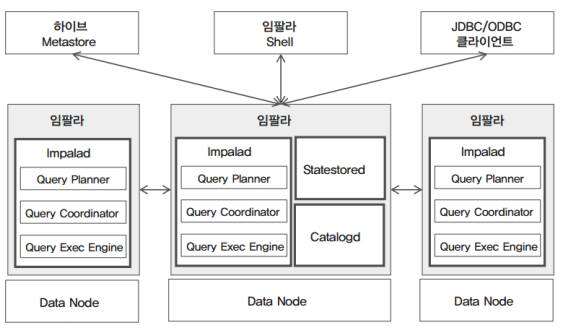
- 하둡의 데이터 노드 위에서 실행된다.
- 데이터 노드 위에 Impalad가 하나씩 올라가고, 그 안에는 Query Exec Engine, Query Planner, Query Coodinator가 설치된다.
- 한 대는 반드시 Master Server가 되어야 한다.
- 마스터 서버에는 Statestored와 Catalogd가 위치한다.
Zeppelin - 제플린
데이터를 분석할 때 많이 사용되는 언어는 R, Python이다. 분석 시 이 언어를 사용할 때는 하둡에 있는 데이터를 JDBC와 같은 커넥터로 연결한 후 데이터를 가져와서 해당 언어에 맞게 데이터를 전처리하고 분석하고 사용하는데는 몇가지 문제가 있다.
첫 번째는 하둡에 있는 빅데이터를 가지고 올 때 저장공간에 대한 Space, Network I/O, Disk I/O에 대한 문제가 발생한다는 것이다.
두 번째는 R과 파이썬 환경으로 빅데이터를 어떻게든 가져갔다고 한들 빅데이터를 사용하기에는 workstation 환경이 부족하다는 것이다.
위와 같은 문제를 해결하기 위해 빅데이터의 컴퓨팅 파워 능력을 사용하여 전처리 작업을 수행한 뒤 경량화 된 데이터를 R 혹은 Python 환경으로 가져가서 분석을 하는 방법으로 사용한다. 하지만 이 또한 하둡에 대한 의존성이 커진다는 문제가 있는데, 이를 해결하기 위한 최적의 도구가 Spark다.
이 Spark의 환경을 웹 환경에서 사용하기 쉽게 인터페이스를 제공해주는 프레임워크가 바로 제플린이다.
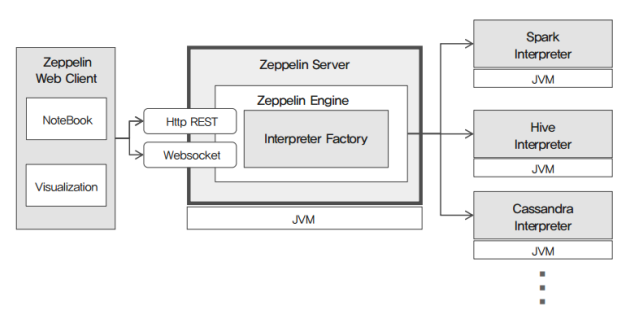
- 주요 구성 요소
- NoteBook
- 웹 상에서 제플린의 인터프리터 언어를 작성하고 명령을 실행 및 관리할 수 있는 UI다.
- Visualization
- 인터프리터의 실행 결과를 곧바로 웹 상에서 다양한 시각화 도구로 분석해 볼 수 있는 기능이다.
- Zeppelin Server
- NoteBook을 웹으로 제공하기 위한 웹 어플리케이션 서버로서, 인터프리터 엔진 및 인터프리터 API 등을 지원한다.
- Zeppelin Interpreter
- 데이터 분석을 위한 다양한 인터프리터를 제공하며, 스파크, 하이브, JDBC, Shell 등이 있으며 필요 시 인터프리터를 추가 확장할 수 있다.
- NoteBook
- 아키텍처
Mahout - 머하웃
하둡 생태계에서 머신러닝을 사용해 데이터 마이닝을 수행하는 소프트웨어
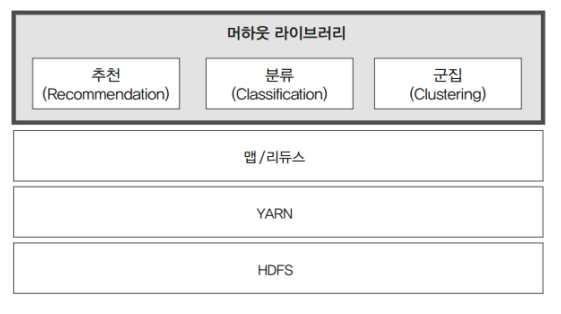
- 주요 구성 요소
- 추천 (Recommendation)
- 사용자들이 관심을 가졌던 정보나 구매했던 물건의 정보를 분석해서 추천하는 기능.
- 사용자 기반 추천
- 유사한 사용자를 찾아서 추천하는 방식
- 아이템 기반 추천
- 항목 간 유사성을 계산해서 추천 항목을 생성하는 방식
- 분류 (Classification)
- 데이터셋의 다양한 패턴과 특징을 발견해 레이블을 지정하고 분류하는 기능
- 나이브 베이지안, 랜덤 포레스트, 로지스틱 회귀 등을 지원한다.
- 군집 (Clustering)
- 대규모 데이터셋에서 새로운 특성으로 데이터의 군집들을 발견하는 기능
- K-Means, C-Means, Canopy 등을 지원한다.
- 감독학습 (Supervised Learning)
- 학습을 위한 데이터셋을 입력해서 분석 모델을 학습시키는 머신러닝 기법
- 학습된 분석 모델을 이용해 예측하고 최적화하는데 사용하고, 분류와 회귀 분석 기법이 이에 해당한다.
- 비감독학습 (Unsupervised Learning)
- 학습 데이터셋을 제공하지 않고 데이터의 특징적인 패턴을 발견하는 머신러닝 기법
- 사람이 구분 및 그루핑하기 어려운 현상들을 자동으로 그루핑하는데 사용
- 군집 기법이 여기에 해당한다.
- 추천 (Recommendation)
- 아키텍처
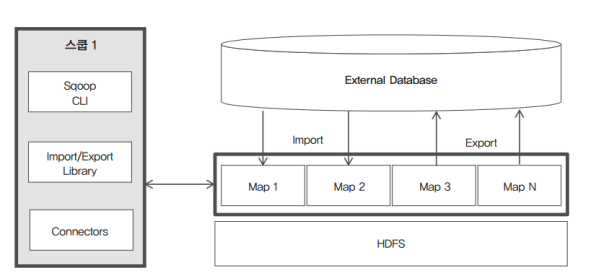
Sqoop - 스쿱
엄밀히는 빅데이터 분석 도구는 아니다. 빅데이터 분석 결과를 하둡에서 외부에 있는 RDBMS에 전달한다던지, 그 반대의 경우에 사용한다.
- 주요 구성 요소
- Sqoop Client
- 하둡의 분산 환경에서 HDFS와 RDBMS간의 데이터 import, export 기능을 수행하기 위한 라이브러리로 구성되어 있다.
- Sqoop Server
- 스쿱 2의 아키텍처에서 제공되며, 스쿱 1의 분산된 클라이언트 기능을 통합하여 REST API로 제공한다.
- Import/Export
- Import
- RDBMS 데이터를 HDFS로 가져올 때 사용한다.
- Export
- HDFS의 데이터를 RDBMS로 내보낼 때 사용한다.
- Import
- Connectors
- Import/Export에서 사용될 다양한 DBMS의 접속 Adaptor와 라이브러리를 제공한다.
- Metadata
- 스쿱 서버를 서비스하는데 필요한 각종 메타 정보를 저장한다.
- Sqoop Client
- 아키텍처 - 1
- 스쿱 클라이언트가 직접 하둡에 접속을 해서 Import/Export를 하기 위한 Map을 실행한다.
- 아키텍처 - 2
- 스쿱 클라이언트는 단지 CLI와 Browser 기능만을 가진다.
- REST API, WEB UI, Import/Export Library, Connectors의 구성요소를 가진 스쿱 서버가 클라이언트와 하둡의 중간에서 상호 접속을 할 수 있는 중간 다리 역할을 수행한다.

'Data Engineering > Big Data' 카테고리의 다른 글
| [빅데이터 탐색] Hive, Spark, Oozie, Hue (0) | 2022.11.07 |
|---|---|
| [빅데이터 실시간 데이터 적재] HBase, Redis, Storm, Espher (0) | 2022.10.26 |
| [빅데이터 수집] Flume, Kafka를 활용한 적재 (0) | 2022.10.25 |
- Total
- Today
- Yesterday
- OS
- 파이썬
- heapq
- cka
- sqoop
- 빅데이터를지탱하는기술
- logstash
- 네트워크
- 프로그래머스
- kafka
- GROK
- mahout
- HDFS
- DP
- kubernetes
- Algorithm
- 백준
- CS
- 이코테
- oozie
- Hadoop
- Flutter
- BOJ
- CSAPP
- DFS
- elasticsaerch
- Espher
- Python
- 빅데이터
- Elasticsearch
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |